TLDR: Im Januar 2022 führten wir – die Visual Computing Gruppe der HTW Berlin – ein Experiment zur Bewertung von Bildsortierungen durch. Dabei konnte gezeigt werden, dass Bilder in sortierten Anordnungen viel schneller gefunden werden. Unser neues Maß zur Bewertung von Bildsortierungen erwies sich als deutlich besser als die üblicherweise verwendeten, um die von Menschen wahrgenommene Sortierqualität zu beschreiben. Zudem konnten unsere vorgeschlagenen Sortierverfahren im Vergleich zu anderen Verfahren viel effizienter qualitativ hochwertige Bildsortierungen erzeugen.
Mehr als 2000 Teilnehmer haben an unserem Experiment teilgenommen, denen wir hier noch einmal danken möchten. Die Ergebnisse wurden in einem Fachartikel (https://onlinelibrary.wiley.com/doi/epdf/10.1111/cgf.14718 ) veröffentlicht, der jedoch für Nicht-Spezialisten möglicherweise schwer zu verstehen ist. Daher versuchen wir hier, die Motivation, die Durchführung und die Ergebnisse des Experiments verständlich zusammenzufassen.
Menschen haben Schwierigkeiten viele Bilder auf einmal zu erkennen
Obwohl Menschen komplexe Bilder schnell erfassen und verstehen können, haben sie Schwierigkeiten, viele Bilder auf einmal zu erkennen. Dieses Problem besteht bei der Suche nach Bildern in Fotoarchiven oder nach Produkten auf E-Commerce-Websites. Hier gestaltet sich die Suche oft sehr schwierig, wenn die Menge der relevanten Ergebnisbildern sehr groß ist. Da auf einem Bildschirm nur 10 – 20 Bilder gleichzeitig wahrgenommen werden können, ist oft ein endloses Scrollen durch unstrukturierte Listen notwendig, um das gesuchte Bild oder Produkt zu finden.
Menschen können Bilder leichter erfassen, wenn sie sortiert angezeigt werden. Die folgende Abbildung zeigt 256 IKEA-Küchengeräte, auf der linken Seite in zufälliger Reihenfolge, auf der rechten Seite nach Ähnlichkeit sortiert. Sucht man ein bestimmtes Bild, besteht im unsortierten Fall nur die Möglichkeit, die Bilder zeilenweise zu “scannen”. In der sortierten Anordnung lässt sich schnell die passende Region identifizieren, in der dann gezielt gesucht werden kann.

256 IKEA-Küchengeräte, links in zufälliger Reihenfolge, rechts nach Ähnlichkeit sortiert
Ziele des Experiments
Das Ziel des durchgeführten Experiments bestand darin, herauszufinden, inwiefern Menschen durch geeignete Sortierungen von Bildern in der Lage sind, mehr Bilder auf einmal zu erfassen und wie dadurch die Zeit zum Finden der Bilder reduziert werden kann. Konkret ging es um folgende Fragen:
- Welche Arten von Bildsortierungen empfinden Menschen als angenehm und hilfreich?
- Wie kann die Qualität einer visuellen Sortierung, wie sie von Menschen empfunden wird, objektiv gemessen werden?
- Welche Verfahren sind am besten geeignet, um effizient Sortierungen zu erstellen, die den Präferenzen der Menschen entsprechen?
Was bedeutet eigentlich “sortieren”?
Bevor wir die im Experiment ermittelten Antworten auf die oben genannten Fragen vorstellen, möchten wir zunächst das Prinzip einer Sortierung anhand eines einfachen Beispiels erläutern. Sollen die Zahlen 6, 5, 2, 8 und 3 nach ihrer Größe sortiert werden, bedeutet dies, dass wir die Zahlen so anordnen müssen, dass jede Zahl größer als die vorherige ist.
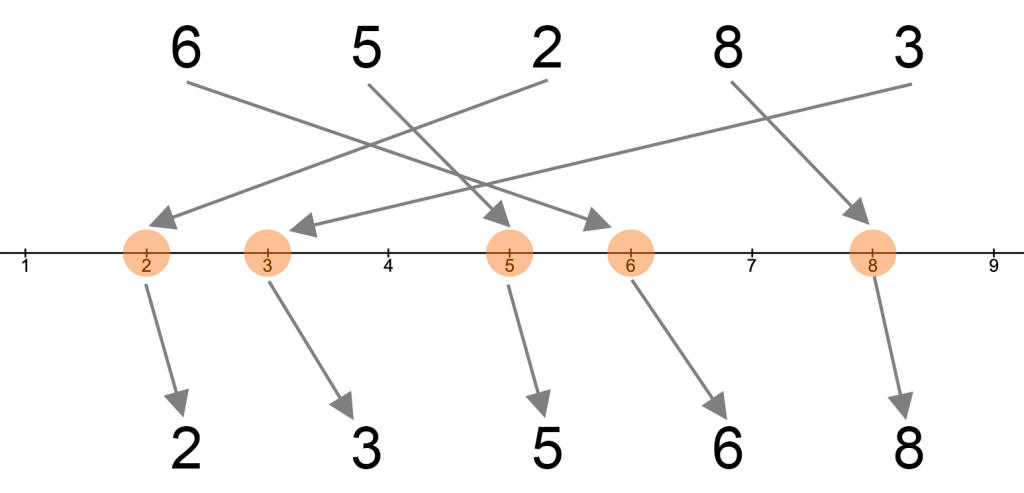
Sortierung von fünf Zahlen
Generell gibt es für n Objekte 1∙2∙3 ∙ … ∙ n = n! (sprich “n Fakultät”) Möglichkeiten, sie anzuordnen. Im Fall unserer fünf Zahlen wären das schon 120 mögliche Anordnungen, von denen nur zwei sortiert sind (aufsteigend bzw. absteigend). Für größere Mengen von Zahlen gibt es effiziente Algorithmen zur Bestimmung der Sortierung (der optimalen Anordnung).
Wie sortiert man Bilder?
Sollen Bilder sortiert werden, ist nicht klar, wie hier eine gute Sortierung überhaupt aussieht und wie sie zu bestimmen ist. Im Vergleich zur Sortierung von Zahlen gibt es zwei wesentliche Unterschiede: Erstens wird das Aussehen und der Inhalt von Bildern nicht durch einzelne Zahlen, sondern mittels sogenannter Featurevektoren beschrieben. D. h. jedes Bild wird durch einen Vektor in einem hochdimensionalen Raum repräsentiert, wobei sich Vektoren ähnlicher Bilder in der Regel nahe beieinander befinden. Zweitens werden die sortierten Bilder meist auf einem 2D-Raster angeordnet, was bedeutet, dass es Nachbarn in horizontaler und vertikaler Richtung gibt. Die Zahl der möglichen Anordnungen wächst wieder faktoriell mit der Anzahl der Bilder. Bei einer Anordnung von 100 Bildern auf einem Raster von 10∙10 Bildern gibt es bereits 100! = 9,3∙10157 Möglichkeiten (eine Zahl mit 158 Stellen), sie anzuordnen. Angesichts einer derart großen Zahl ist es selbst mit schnellsten Computern unmöglich, alle Varianten auszuprobieren. Selbst wenn es möglich wäre, alle Anordnungen zu vergleichen, wäre nicht klar, welche am besten sortiert ist.
Um das Prinzip der Sortierung von Bildern zu verdeutlichen, kann die zweidimensionale Sortierung von Farben als Beispiel dienen. Farben werden durch ihre Rot-, Grün- und Blau-Anteile beschrieben und können somit als 3D-Vektoren dargestellt werden. Um Farben zweidimensional zu sortieren, müssen diese 3D-Vektoren einem Platz auf einem 2D-Raster zugeordnet werden. Die folgende Abbildung zeigt eine mögliche sortierte Anordnung von 9∙9∙9 (= 729) RGB-Farben auf einem 2D-Raster mit 27∙27 (= 729) Positionen.
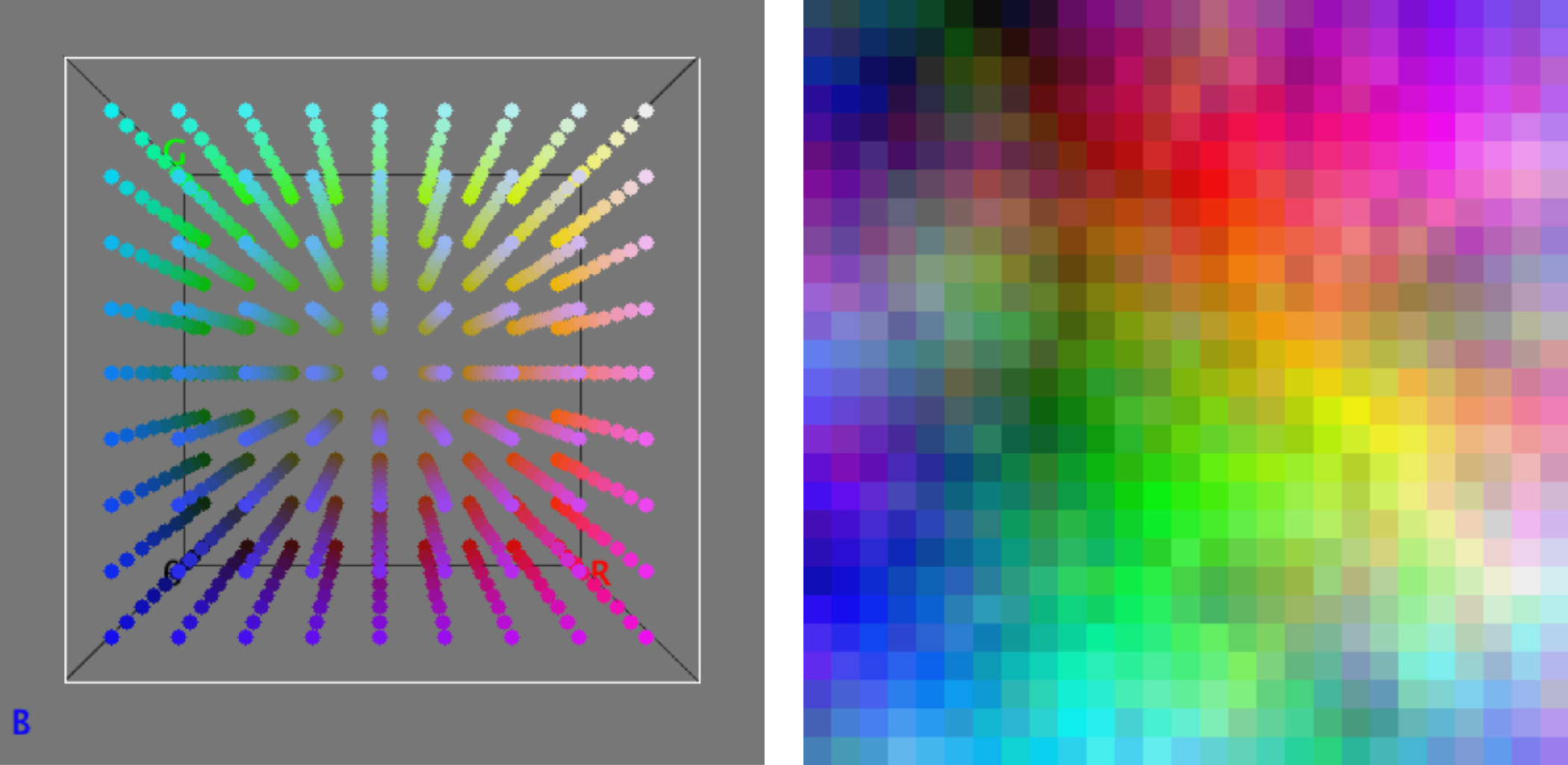
729 Farben im 3D RGB-Farbraum ➞ 729 Farben angeordnet auf einem 2D Raster
Der Unterschied der visuellen Sortierung von Bildern im Vergleich zum oben genannten Farbbeispiel besteht nur darin, dass die Dimensionen der Featurevektoren von Bildern sehr viel höher sind. Zur Beschreibung der visuellen Erscheinung eines Bildes reichen weniger als 100 Dimensionen aus, während für die Beschreibung des Bildinhaltes Tausende von Dimensionen erforderlich sein können.
Verwendete Bildsets
Vor der Durchführung des Experiments haben wir Untersuchungen mit verschiedenen Bildsets unterschiedlicher Größe durchgeführt. Dabei zeigte sich, dass bei zu großer Bildanzahl einige Bilder unabhängig von ihrer Sortierung sehr schwer zu finden waren. Dies hätte bei Suchaufgaben während des Experiments sicherlich zum Abbruch vieler Teilnehmer geführt. Bei sehr kleinen Sets hingegen hatte die Sortierung der Bilder kaum einen Einfluss auf die Suchzeit, da die gesuchten Bilder meist sofort erkannt und gefunden wurden.
Im Experiment wurden vier verschiedene Sets verwendet. Das erste bestand aus 1024 zufällig generierten RGB-Farben und wurde nur zur Ermittlung der empfundenen Qualität unterschiedlicher Sortierungen genutzt. Für drei weitere Bildsets wurde zusätzlich die Zeit zum Finden von gesuchten Bildern erfasst. Diese drei Bildsets wurden so ausgesucht, dass sie einerseits unterschiedliche Such-Szenarien abbilden und es weiterhin einen signifikanten Unterschied bei der Suchgeschwindigkeit zwischen sortierten und zufälligen Anordnung gab. Das erste Set bestand aus 169 Verkehrszeichen, wie sie auf Übersichtstafeln abgebildet sein könnten. Das zweite Set bestand aus 256 Bildern von IKEA Küchenartikeln, wie sie typischerweise auf E-Commerce-Websites präsentiert werden. Das letzte Set waren 400 Bilder zu 70 nicht verwandten Suchbegriffen, die aus dem Internet gecrawlt wurden. Dieses Set könnte eigene Fotos repräsentieren. Die folgende Abbildung zeigt die vier verwendeten Sets, jeweils in der Sortierung, die von den Teilnehmern am besten beurteilt wurde.
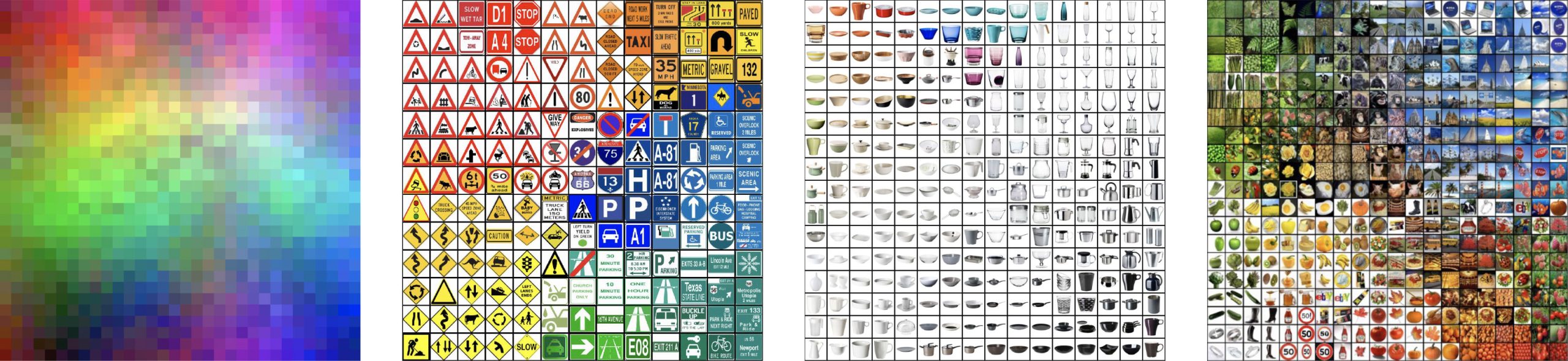
Die vier Testsets des Experiments: 1024 RGB-Farben, 169 Verkehrszeichen, 256 Küchenartikel und 400 Bilder zu 70 Suchbegriffen aus dem Internet
Durchführung des Experiments
Das Experiment bestand aus zwei Teilen. Im ersten Teil wurden die Präferenzen der Teilnehmer erfasst, indem sie Paare von sortierten Bildanordnungen betrachten und entscheiden sollten, welche der beiden Anordnungen ihnen besser gefällt. Dabei sollten die Anordnungen bevorzugt werden, die “eine klarere Struktur aufweisen, einen besseren Überblick bieten und das Auffinden gesuchter Bilder erleichtern”. Im zweiten Teil des Experiments sollten die Teilnehmer in sortierten Anordnungen möglichst schnell gesuchte Bilder finden. Dabei wurde überprüft, ob die von den Teilnehmern bevorzugten Sortierungen auch eine schnellere Suche ermöglichen. Darüber hinaus haben wir untersucht, wie gut sich die Suchzeit mit Hilfe der Sortierqualität vorhersagen lässt.
Untersuchte Sortierverfahren und Qualitätsmaße
In unseren Experimenten haben wir verschiedene Methoden zur Erzeugung sortierter Anordnungen verwendet. Neben Self Organizing Maps (SOM) kamen Self Sorting Maps (SSM), IsoMatch und eine diskrete t-SNE Projektion zum Einsatz. Wir haben diese Methoden mit unseren eigenen Ansätzen Linear Assignment Sorting (LAS) und Fast Linear Assignment Sorting (FLAS) verglichen. Weitere Details zu den jeweils verwendeten Algorithmen finden sich in unserer oben zitierten Veröffentlichung. Falls möglich, haben wir für jedes Verfahren mehrere Sortierungen mit unterschiedlichen Parametereinstellungen generiert. Um auch Beispiele geringer Sortierqualität zum Vergleich zu haben, wurden auch einige schlecht sortierte Anordnungen (bezeichnet mit “low Qual.”) erzeugt. Rein zufällige Anordnungen wurden nicht verwendet, da dies wieder zu Experimentabbrüchen geführt hätte, weil das Finden der Bilder häufig zu schwierig gewesen wäre.
Es gibt Maße zur Bewertung von 2D-Sortierungen, aber es gibt keine Untersuchungen, die zeigen, wie gut diese die von Menschen wahrgenommene Qualität widerspiegeln. Diese Qualitätsmaße vergleichen die Abstände der Featurevektoren im Hochdimensionalen mit den resultierenden Abständen der Bilder auf dem 2D-Raster. Üblicherweise werden die Kreuzkorrelation bzw. die normalisierte Energiefunktion verwendet, die sich jedoch beide sehr ähnlich verhalten, weshalb wir nur die letztere verglichen haben. Wir haben ein neues Maß namens “Distance Preservation Quality” (DPQ) zur Bewertung von 2D-Sortierungen vorgeschlagen.
Empfundene Sortierqualität
Die nächste Abbildung zeigt einen Screenshot des ersten Teils des Experiments. Allen Teilnehmern wurden 16 Paare von Sortierungen gezeigt und sie sollten jeweils entscheiden, ob sie die linke oder die rechte Sortierung bevorzugen oder beide für gleichwertig halten.

Screenshot des ersten Teils des Experiments
Um eine mögliche Beeinflussung der Ergebnisse durch unsinnige Bewertungen auszuschließen, wurde in jedem Experiment ein Paar mit extrem unterschiedlicher Sortierqualität angezeigt. Wenn ein Teilnehmer bei diesem Paar die deutlich schlechte Sortierung bevorzugte, wurden seine Entscheidungen für alle Sortierungen verworfen. Insgesamt wurden 32 Sortierungen für das Farbset und jeweils 23 Sortierungen für die drei Bildsets untersucht. Entsprechend der Fußball-Bundesliga, wo es mit 18 Mannschaften 18∙17 = 306 Hin- und Rückspiele gibt, was 153 unterschiedlichen Paarungen entspricht, gab es hier beim Experiment 496 mögliche Paare für das Farbset und jeweils 253 mögliche Paare für die drei Bildsets.
Zur Auswertung aller Vergleiche wurde ein ähnliches Verfahren wie beim Fußball angewendet, wo ein Spiel mit einem Sieg, einer Niederlage oder unentschieden enden kann. Beim Vergleich zweier Sortierungen erhielt die bevorzugte Sortierung einen Punkt. Wenn beide Sortierungen als gleichwertig bewertet wurden, erhielten beide einen halben Punkt. Im Gegensatz zum Fußball, bei dem es pro Saison zwei Spiele zwischen zwei Mannschaften gibt, wurde jedes Sortierungs-Paar mindestens 35 mal von unterschiedlichen Teilnehmern bewertet. Aus diesen Bewertungen wurde für beide Sortierungen einer Paarung jeweils die durchschnittliche Punktzahl ermittelt. Diese beiden Punktzahlen, die in Summe 1 ergeben, beschreiben, in welchem Verhältnis die eine Sortierung besser als die andere bewertet wurde. Für den Gesamtvergleich aller Sortierungen wurden ihre erhaltenen Punktzahlen aus allen Paar-Vergleichen addiert.
Ein Qualitätsmaß, das die Sortierqualität bewertet, sollte möglichst stark mit der Qualitätsbewertung der Nutzer übereinstimmen. Die folgenden Abbildungen zeigen den Zusammenhang (die Korrelation) der durchschnittlichen Nutzerbewertung der Sortierungen (User Score) im Vergleich zu den beiden untersuchten Qualitätsmaßen. Hierbei steht E’1 für die üblicherweise verwendeten “normalisierten Energiefunktion” und DPQ für die von uns vorgeschlagene “Distance Preservation Quality”. Die Symbolfarben repräsentieren die verschiedenen Sortierverfahren.
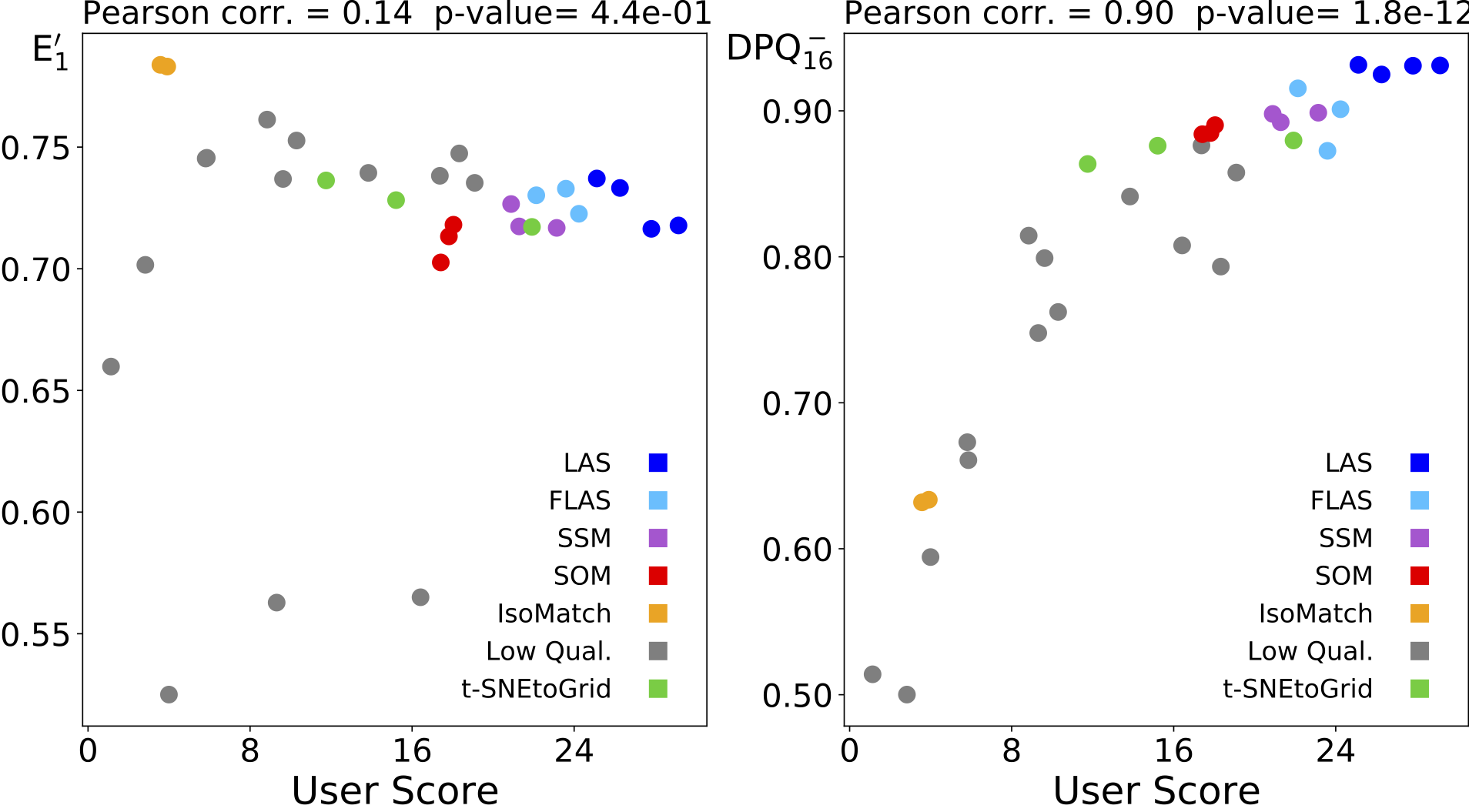
Sortierungen der 1024 RGB-Farben: Korrelation zwischen Nutzerbewertungen und der normalisierten Energiefunktion (links) bzw. unser Distance Preservation Quality (rechts). Man erkennt links z.B., dass von Menschen besser bewertete Sortierungen von der “normalisierten Energiefunktion” als schlechter angesehen werden. Die Werte der “Distance Preservation Quality” (rechts) hingegen steigen bei besser bewerteten Sortierungen.
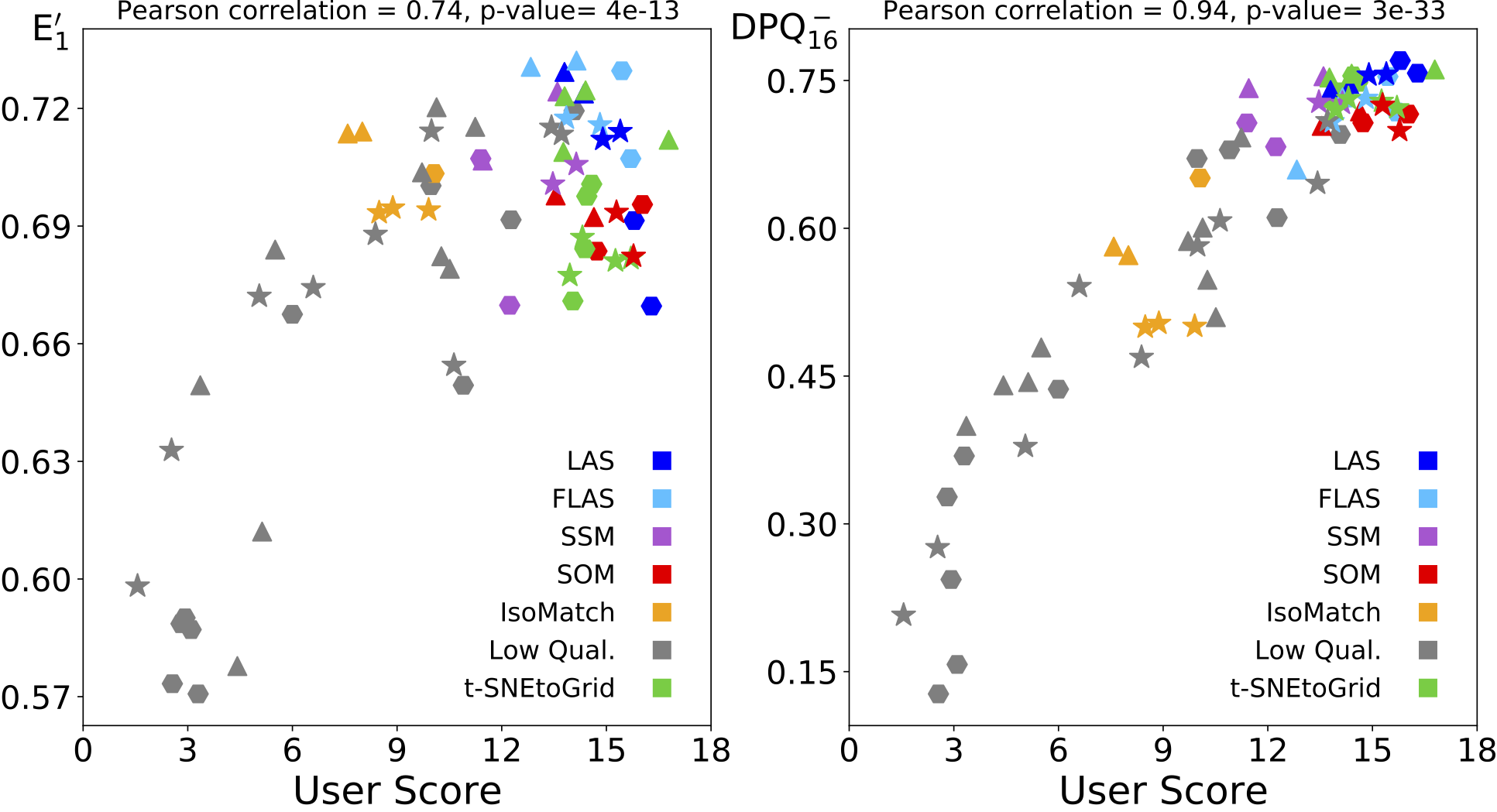
Sortierungen der Bildsets: Korrelation zwischen Nutzerbewertungen und normalisierter Energiefunktion (links) bzw. unser Distance Preservation Quality (rechts). Die Symbolformen kennzeichnen die Bildsets: Verkehrszeichen (⬢), Küchenartikel (▲) und Internet-Bilder (★).
Die beiden Abbildungen zeigen, dass unser neues DPQ-Maß eine höhere Korrelation mit den Nutzerbewertungen aufweist, was bedeutet, dass es besser geeignet ist, die von Menschen empfundene Sortierqualität vorherzusagen.
Suchzeiten
Im zweiten Teil des Experiments wurden den Nutzern verschiedene sortierte Anordnungen gezeigt, in denen jeweils vier zufällige Bilder zu finden waren. War ein Bild gefunden, wurde sofort das nächste angezeigt. Die verwendeten Sortierungen waren dieselben wie im ersten Teil des Experiments.

Screenshot des zweiten Teils des Experiments
Natürlich hängt die Schwierigkeit, Bilder zu finden, stark von den gesuchten Bildern ab, da einige Bilder auffälliger sind als andere. Darüber hinaus unterscheiden sich die Teilnehmer in ihren Suchfähigkeiten. Bei nur wenigen Versuchen könnten diese beiden Aspekte die Ergebnisse erheblich verfälschen. Insgesamt wurden jedoch mehr als 28.000 dieser Suchaufgaben durchgeführt. Das bedeutet, dass für jede Sortierung mehr als 400 Suchen für jeweils vier Bilder durchgeführt wurden. Durch diese hohe Anzahl wurden sowohl die unterschiedlich schwierigen Suchaufgaben als auch die ungleichen Fähigkeiten der Teilnehmer ausgeglichen.
Die nächsten Abbildungen zeigen die Verteilung der Suchzeiten der 23 unterschiedlichen Sortierungen für das Set der Verkehrszeichen (Traffic Signs) und der Internet-Bilder (Web Images). Die Medianwerte der Suchzeiten für die verschiedenen Sortierungen sind als farbige Markierungen dargestellt. Auch hier zeigt sich die stärkere (negative) Korrelation der Suchzeiten mit unserem DPQ-Maß im Vergleich zur normalisierten Energiefunktion.
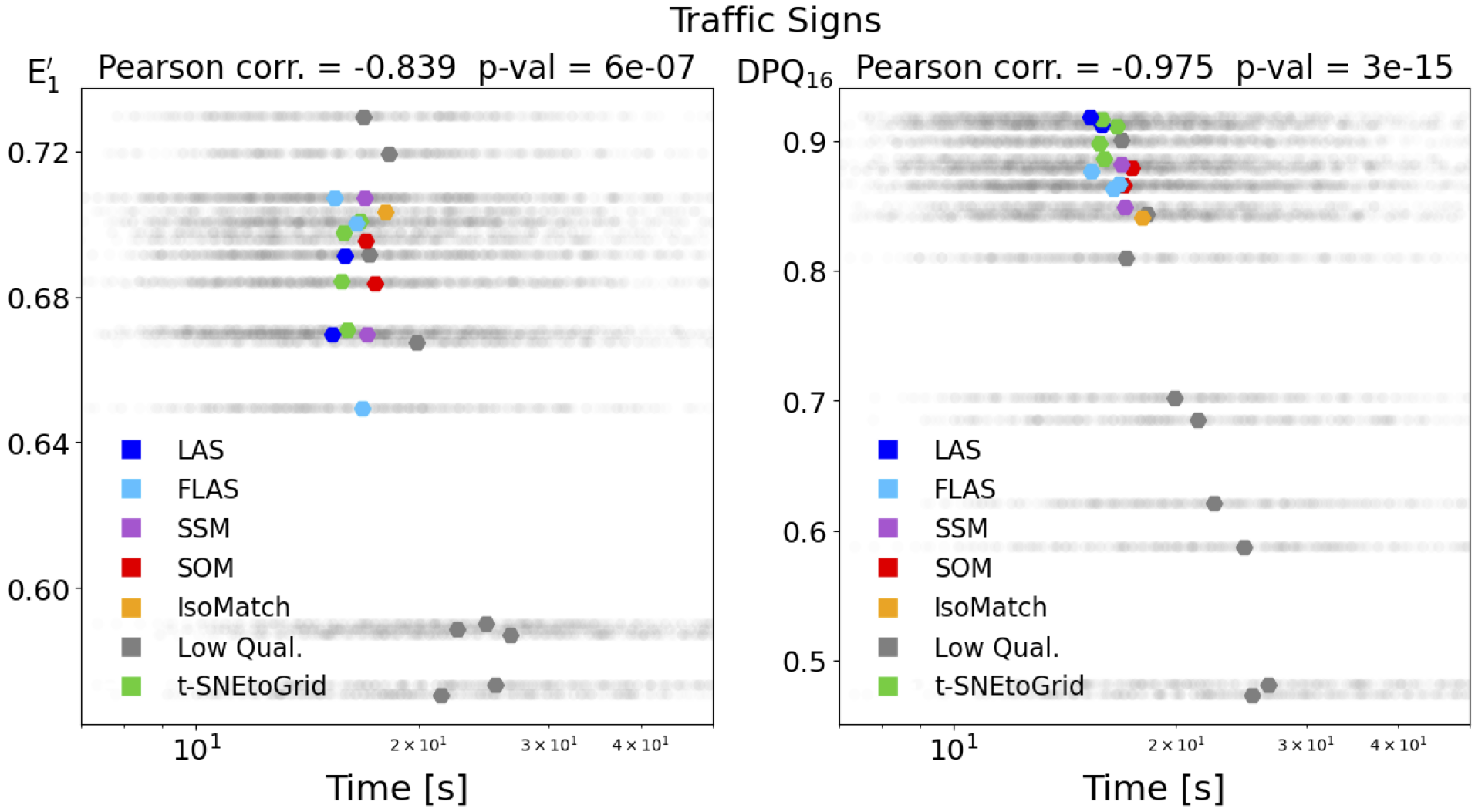
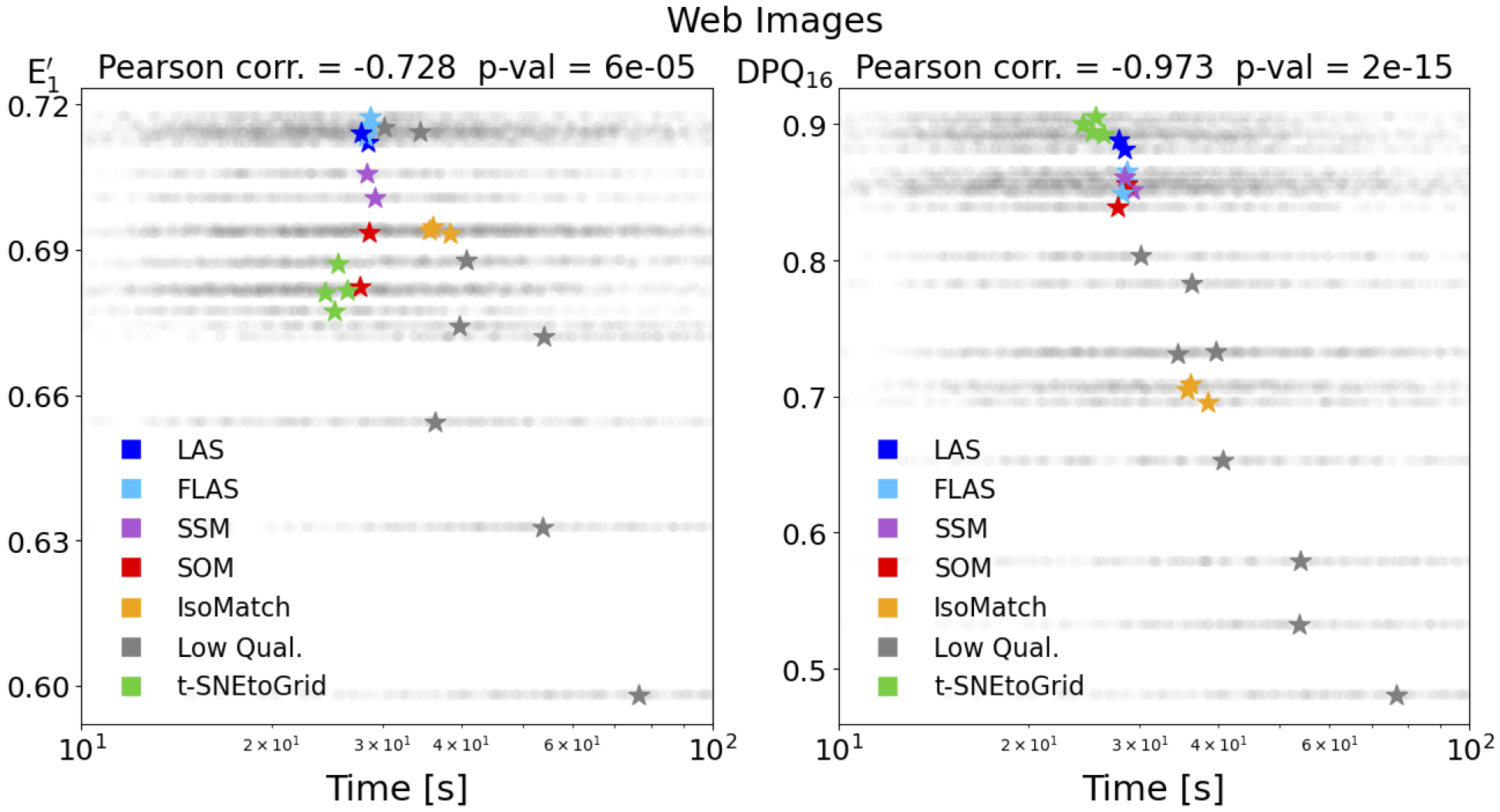
Korrelation der Medianwerte der Suchzeiten mit normalisierter Energiefunktion (links) und unser Distance Preservation Quality (rechts)
Beim Vergleich der Sortierungen, die eine hohe Suchgeschwindigkeit ermöglichen, mit denen, die besonders gut bewertet wurden, zeigte sich ebenfalls eine starke Übereinstimmung. Jedoch war es für ein schnelles Finden wichtiger, dass alle ähnlichen Bilder sehr nah beieinander angeordnet waren, auch wenn die globale Anordnung der Sortierung dadurch etwas schlechter bewertet wurde. Die nächste Abbildung zeigt links für das Internet-Bilder-Set die Sortierung, die am besten bewertet wurde, rechts ist die Sortierung zu sehen, bei der die Bilder am schnellsten gefunden wurden. Links sind die Übergänge fließender, auf der rechten Seite sind jeweils alle zusammengehörigen Bilder dicht beieinander, dadurch entstehen z. T. harte Übergänge.

Links die am besten bewertete Sortierung, rechts die Sortierung, bei der die gesuchten Bilder am schnellsten gefunden wurden
Vergleich der Sortierverfahren
Der letzte Schritt bestand darin, ein besseres Verständnis für die Leistungsfähigkeit der unterschiedlichen Sortierverfahren zu erlangen. Da die Laufzeit stark von der Hardware abhängt, dienen die angegebenen Zeiten nur als Vergleichswerte. Da die Distance Preservation Quality eine hohe Korrelation mit den Nutzerpräferenzen aufweist, wurde sie verwendet, um die Sortierqualität der Algorithmen in Abhängigkeit von der benötigten Rechenzeit zu vergleichen.
Die nächste Abbildung zeigt für die untersuchten Verfahren die erreichte Sortierqualität im Verhältnis zur benötigten Rechenzeit bei Variation der Verfahrensparameter. Bei kleineren Datensätzen wie den 256 Küchenartikel-Bildern bietet unser FLAS-Verfahren den besten Kompromiss zwischen Qualität und Rechenzeit. LAS und t-SNE können geringfügig höhere Qualitäten liefern, sind dabei aber 10 bis 100 mal langsamer. Für die 1024 zufälligen RGB-Farben erzielten unsere LAS- und FLAS-Verfahren die höchsten Sortierqualitäten.
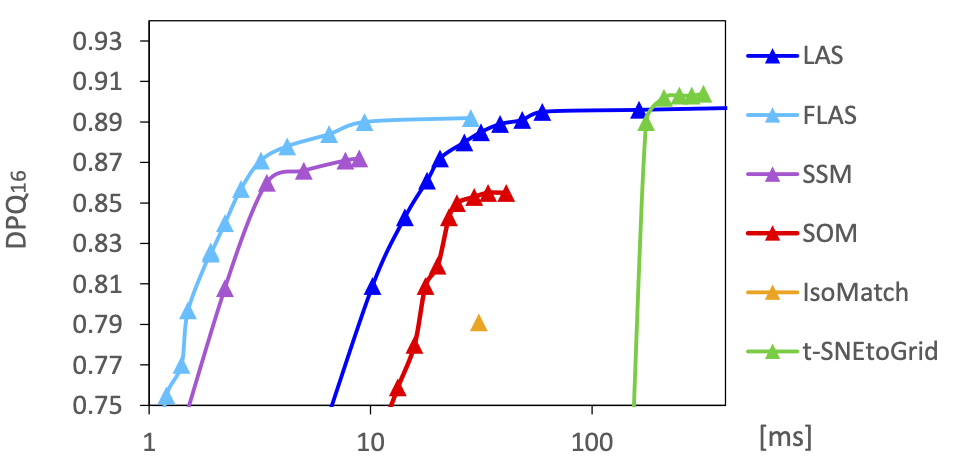
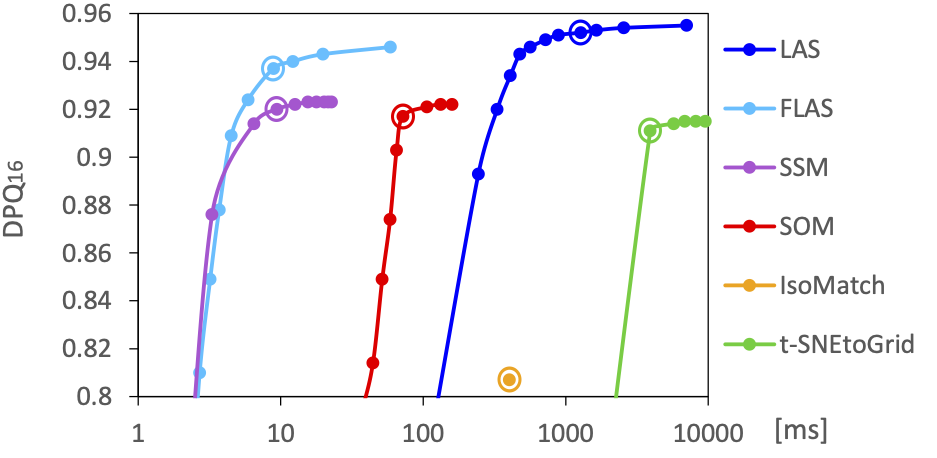
Mittlere Sortierqualität (DPQ) im Vergleich zur mittleren Laufzeit für unterschiedliche Parametereinstellungen für die Sortierungen der 256 Küchenartikel-Bilder (oben) und den 1024 RGB-Farben (unten).
Eine weitere Untersuchung bestand darin, zu überprüfen, wie sich Qualität und Rechenzeit für unterschiedlich große Bildsets verhält. Hierbei wurden die Parametereinstellungen gewählt, die mit den ⦿-Markierungen in der letzten Abbildung gekennzeichnet sind. Während SOM, SSM, LAS und FLAS bei mehr Bildern eine bessere Sortierung generieren können, wurden bei t-SNE und IsoMatch die Sortierungen schlechter.
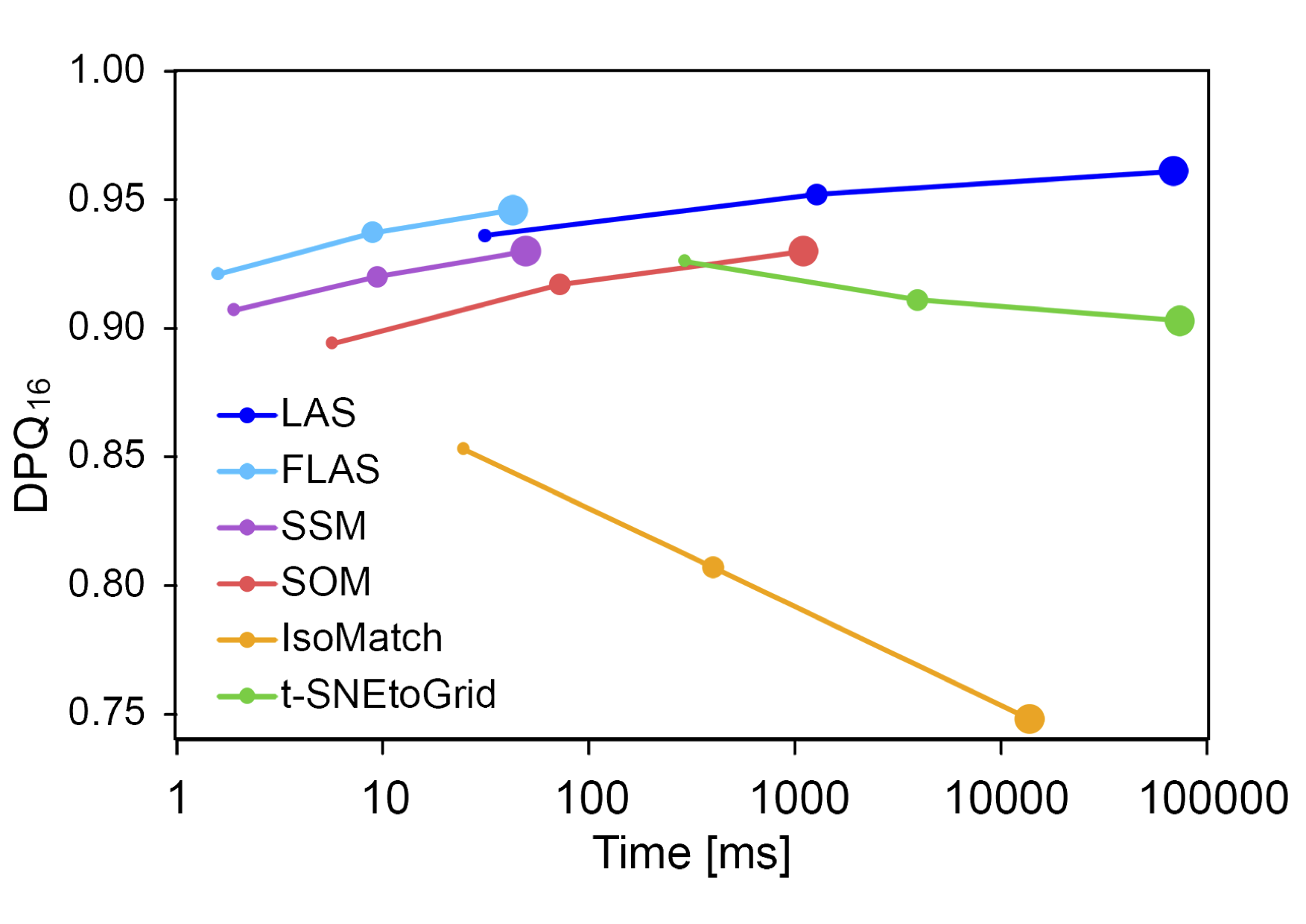
Die mittlere erzielte Sortierqualität in Abhängigkeit von der benötigten Rechenzeit für 256 (⚈), 1024 (⚈) und 4096 (⚈) RGB-Zufallsfarben für die unterschiedlichen Sortierverfahren.
Ergebnisse des Experiments
Insgesamt waren wir mit den Ergebnissen des Experiments sehr zufrieden, da die zuvor gestellten Fragestellungen klar beantwortet werden konnten. Es hat sich gezeigt, dass Menschen in sortierten Anordnungen Bilder deutlich schneller finden können. Bei der Analyse von Bildsortierungen, die Menschen als angenehm und hilfreich empfinden, zeigte sich, dass eine hohe lokale Ähnlichkeit der benachbarten Bilder wichtiger ist, als das globale Erhalten der Ähnlichkeitsbeziehungen aller Bilder. Weiterhin hat sich bestätigt, dass unser Vorschlag für eine neue Qualitätsbewertung von Bildsortierungen erheblich besser als bisherige Verfahren die von Menschen empfundene Qualität widerspiegelt. Es wurde deutlich, dass unsere vorgeschlagenen Sortierverfahren LAS und FLAS qualitativ hochwertige Sortierungen erzeugen können und FLAS dabei auch sehr effizient ist. Darüber hinaus bieten unsere Verfahren eine Vielzahl von Optionen, um die Sortierungen zu beeinflussen, wie beispielsweise die feste Positionierung bestimmter Bilder oder die Möglichkeit andere Layouts als rechteckige zu verwenden. Das FLAS-Verfahren (zusammen mit einem Bildergraphen) ist so schnell, dass es möglich wird, Millionen von Bildern visuell zu explorieren. Navigu.net ist ein Beispiel eines solchen visuellen Bildexplorationstools.

Links: Sortierte Fahnen, mit fester Position der amerikanischen Flagge unten in der Mitte. Rechts: 2404 RGB-Farben in Form eines Herzens sortiert.
One Reply to “Das Bildsortierungs-Experiment”